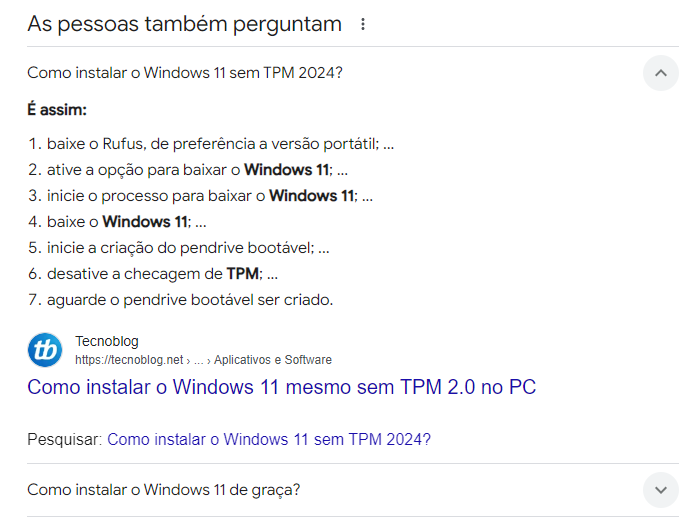
Ou estamos criando conteúdo para o Google usufruir?
Acredito que a notoriedade do site se deva ao fato do mesmo ser um local especializado em diversos assuntos, onde, removendo o site de buscadores, tornará o site fantasma pois não haverá novos usuários acessando, ocasionando uma queda no faturamento.
Remover o site do buscador, trará mais prejuízo do que lucro acredito eu, que seguindo o mesmo exemplo de que o Reddit foi removido de alguns buscadores, com exceção do Google, para o Reddit talvez tenha sido vantajoso pelo acordo, agora para os demais buscadores é uma grande perca.
Inclusive, os buscadores não conseguiram exibir o conteúdo totalmente, então de uma maneira ou de outra, o usuário terá de entrar aqui.
Anteontem li um artigo num site anti-AI (com o qual não totalmente concordo, mas que traz pontos válidos para o debate) que compartilharam no fediverse, entitulado “Google is no longer asking — feed the AI or you’re not in search results”.
Pra resumir o artigo, o Google tem desobedecido as instruções no robots.txt dos domínios, que especifica aos crawlers o que devem e o que não devem percorrer/acessar/indexar. Nessa desobediência, o Google tem usado seu crawler (Googlebot) para alimentar sua IA (Gemini), embora não o modo chat do mesmo (que usa outro User-Agent com o nome de Gemini) mas nesse modo aí de sumarização. Os sites começaram a reclamar e o Google, segundo a Bloomberg, deu o seguinte ultimato: “Compartilhe seus dados (com a IA) ou deixe de constar nos índices de busca”.
Voltando ao caso do Tecnoblog, estava verificando o robots.txt e não há nenhum Disallow: para o /responde/ (onde essa matéria aí, “Como instalar o Windows 11 mesmo sem TPM 2.0 no PC - Tecnoblog”, está) do site. Porém, mesmo que tivesse, é bem capaz do Google continuar alimentando a IA deles.
E Google não é o único fazendo isso, pois no Bing ocorre algo similar ou até pior: a busca do Bing é integrada ao Copilot e quando você arrasta a tela pra cima, o Bing Search alterna para a tela do Bing Copilot, trazendo a sumarização dos principais resultados.
E discorrendo sobre essa pergunta:
Tudo que está sendo dito por nós, tem e está alimentando IAs, não só Google. A Hidra tem várias cabeças. Por um lado “bom”, é graças à essa alimentação que os sistemas de filtragem e moderação automática têm se tornado melhores, porque não basta simplesmente filtrar uma palavra ou um conjunto de caracteres, e Tom Scott tem um vídeo (Youtube) que ilustra isso perfeitamente. É necessário considerar o contexto de uma palavra, senão, por exemplo, tutoriais elaborados por programadores PHP que usem do explode() podem ser filtrados por “apologia à violência e terrorismo”, ou a função de total parcial do NumPy (np.cumsum) pode ser filtrado como sendo “conteúdo adulto” (por causa das três primeiras letras), ou “dibenzofenazina” pode ser filtrado por “apologia a discursos de ódio” (por causa de quatro letras ali dentro da palavra). Uma IA que considera o contexto de uma palavra precisa, antes, saber como funciona contextos e pra isso precisa de um enorme corpo de textos, como uma criança que precisa ler aqueles vários livros (Camões, Machado de Assis, etc) na escola para aprender língua portuguesa.
Há também outra coisa acontecendo, conteúdo de IA alimentando IA, o chamado “AI slop”. Isso faz a amostra ficar limitada e a saída mais incongruente. Junto à isso, existem artistas e escritores tentando sabotar a IA com “cavalos de tróia artísticos” no meio do conteúdo, de forma que a IA “bugue” em sua aprendizagem. Não vai tardar para que Google, Microsoft, OpenAI, Anthropic, Meta e outras criem IAs para filtrar o slop e as sabotagens.
É um caminho sem volta, em minha opinião. A IA já está devorando tudo o que dissemos hoje e no passado (até mailing lists de Bulletin Board Systems (BBS) e conversas antigas do IRC não escapam, pois seus arquivos e históricos estão indexados na Internet e com certeza já foram assimilados), e sua fome por dados não cessará (a ponto de consumir a si mesma, como mencionei acima). Talvez os confins da internet (como a rede Onion) ainda não estejam sendo usados para treinar IA, mas nem o fediverse está livre disso (porque um servidor faz federação com outro que, por sua vez, faz federação com o Threads da Meta e aí, bom, a Meta dispensa apresentações…).
Se não concordasse era só
meta name=“robots” content=“noindex, nofollow”
Infelizmente isso não funciona mais.
Provas? Veja o robots.txt do Reddit: para qualquer crawler, o Reddit Disallow: o escopo principal do domínio (ou seja, todo o site). Ou seja, o robots.txt do Reddit não permite que o site seja indexado.
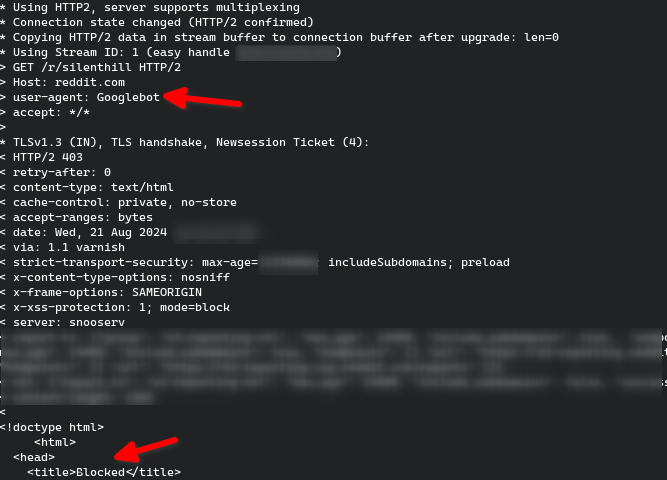
Também há bloqueio server-side quando o User-agent pertence a algum crawler, como no exemplo que acabei de testar (comando curl -v https://reddit.com/r/silenthill -A "Googlebot":
No entanto…

Ora… Se o Googlebot, crawler oficial do Google, é bloqueado tanto por robots.txt quanto por análise no server-side, como o resultado ainda aparece no Google? A resposta é bem simples: eles não só ignoram o robots.txt (e por consequência o meta name="robots") como estão burlando os mecanismos anti-crawler (provavelmente fingindo ser um Chrome, ou um Chrome Android, passando os cabeçalhos destes durante a requisição).
No caso do Reddit, em específico, o site tem um acordo de exclusividade com a Google. Recentemente começaram a bloquear outros provedores de busca de indexar o site…
Recentemente começaram a bloquear outros provedores de busca de indexar o site
Sim, sim, tô ligado nesse acordo. Mas será que isso tem funcionado com outros indexadores?
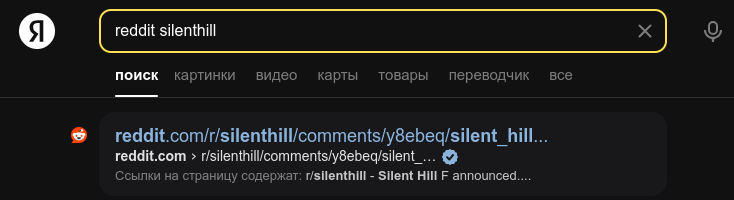
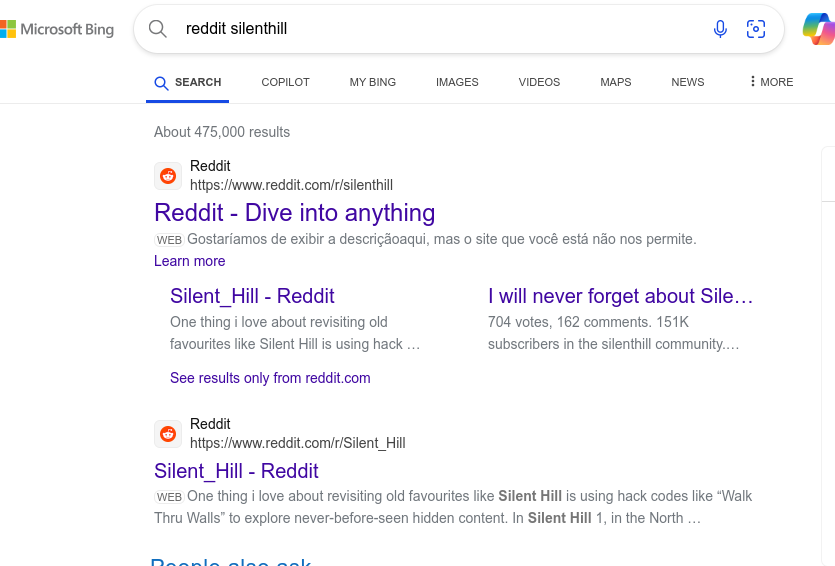
O Baidu foi o único que testei que realmente não exibiu nada do Reddit (e a busca por site:reddit.com silenthill retornou um texto em mandarim que eu creio ser algo como “não há nenhum resultado” porque não entendo mandarim)
EDIT: E outra coisa, existe essa parceria Reddit-Google porém o Reddit continua bloqueando diretamente o User-Agent Googlebot, como visto na requisição que fiz via curl, como pode isso?
Infelizmente há inúmeros artigos mostrando que os crawlers não estão mais honrando essas instruções.
As empresas de IA estão coletando e usando as informações mesmo assim.
1 curtida
É a ilusão da escolha que joga o ônus pro lado mais fraco do elo.
Este tópico foi fechado automaticamente 90 dias depois da última resposta. Novas respostas não são mais permitidas.